
Manufacturing - Semi-Supervised Learning for Defect Detection in Additive Manufacturing
Advanced manufacturing is vital for expeditionary manufacturing tasks with limited conventional industrial infrastructure and scarce resources. Among all the latest advancements, the metal Additive Manufacturing (AM) process can best produce complex parts with unconventional materials and geometries without special tooling, while minimizing the usage of raw materials. However, most existing metal-based AM systems have build volume limitations, restricting fabrication to only small and medium-sized parts. This explains why subtractive manufacturing, casting, welding, or sub-assembly processes still dominate, as these large-sized part fabrication techniques retain an edge over the limitations of current metal AM methods.
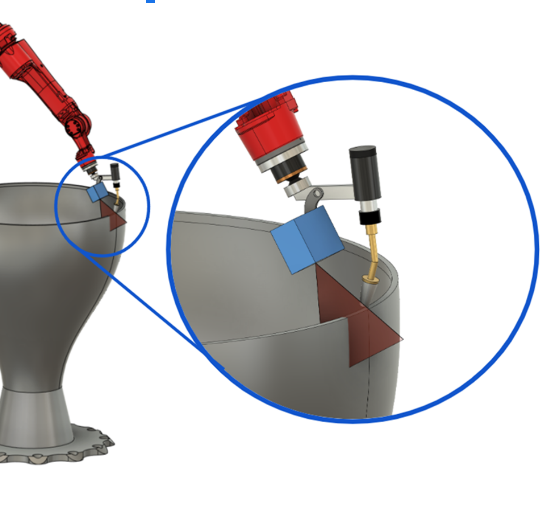
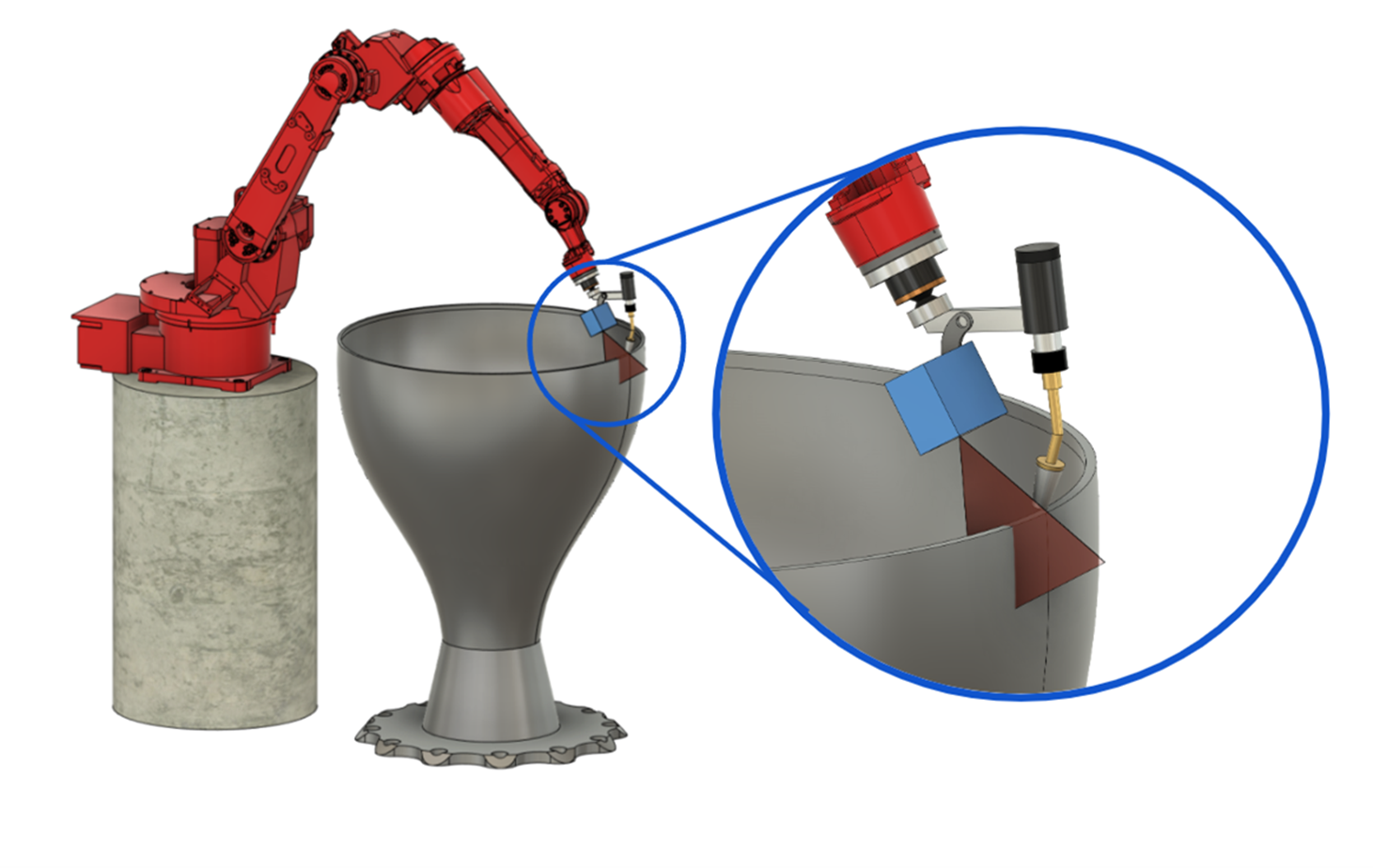
Our research aims to introduce in-process robotic inspection and associated path-planning algorithms to augment existing AM workflows with an intelligent process monitoring system. Our method can eliminate additional post-inspection procedures to reduce both process overall lead time and associated costs. We aim to 1) On-the-fly detect and flag macro-scale defects such as residual stress-related deformation and weld overflow that impact geometric accuracy; 2) Provide in-situ reconstruction of the part geometry and part quality monitoring as an online inspection tool and source of information to understand defect evolution during layer-by-layer manufacturing.

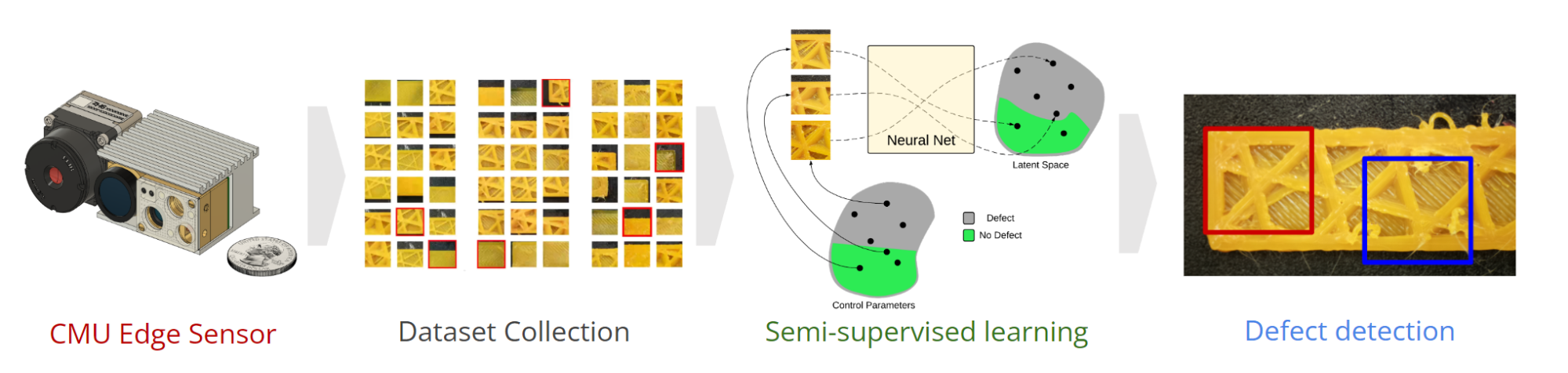
There are two primary challenges when trying to apply machine learning methods to additive manufacturing. First, collecting data samples is extremely time consuming and expensive, so typical datasets consist of only hundreds of samples. Second, the variety of possible defects makes it difficult, if not impossible, to use supervised learning to train a network to identify any type of defect. To tackle these challenges, we propose using a semi-supervised learning framework, split into pre-training and fine-tuning phases.
First, we pre-train a neural network with unlabeled data using a contrastive loss function. The input image data is first augmented with crops, rotations, and random brightness before being fed into two copies of the same neural network. The resulting embedding vectors are then compared using a contrastive loss function which aims to learn a distance metric induced by the samples’ process parameters. Furthermore, we use the theory of Isometric Approximation to prove that problems decidable using the process parameters will be similarly decidable using the learned image embeddings.
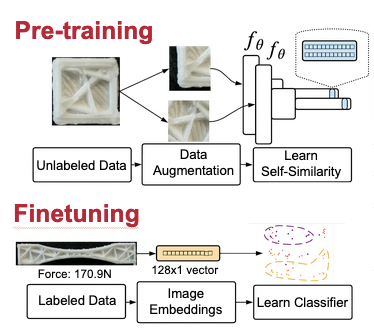
After the network is finished pre-training, its weights are frozen and a specialized “head” network is appended for each desired classification or regression task. Typically these task heads can be as simple as a linear classification model or a linear regression. In addition, the task head can be learned with as few as 40 labeled images and taking only a matter of minutes. And the fine-tuning dataset needs not intersect with the pre-training dataset. Thus whenever a new defect type arises or when the manufacturing objective changes, our trained network can quickly adapt without needing a lengthy retraining process.